Failure States of Virtual SAN Components:
Virtual SAN handles failures of the host, network and storage devices in the cluster based on the severity of the failure. When these fail they directly affect the components in the vSAN cluster.
Virtual SAN has 2 types of failure states for components ABSENT and DEGRADED. According to the component state, it uses different approaches to recover the affected components.
Degraded:
"A component is in degraded state if Virtual SAN detects a permanent component failure and assumes that the component is not going to recover to working state."
Absent:
"A component is in absent state if Virtual SAN detects a temporary component failure where the component might recover and restore its working state."
An ABSENT state may or not resolve itself over time, but a DEGRADED state is a permanent state.
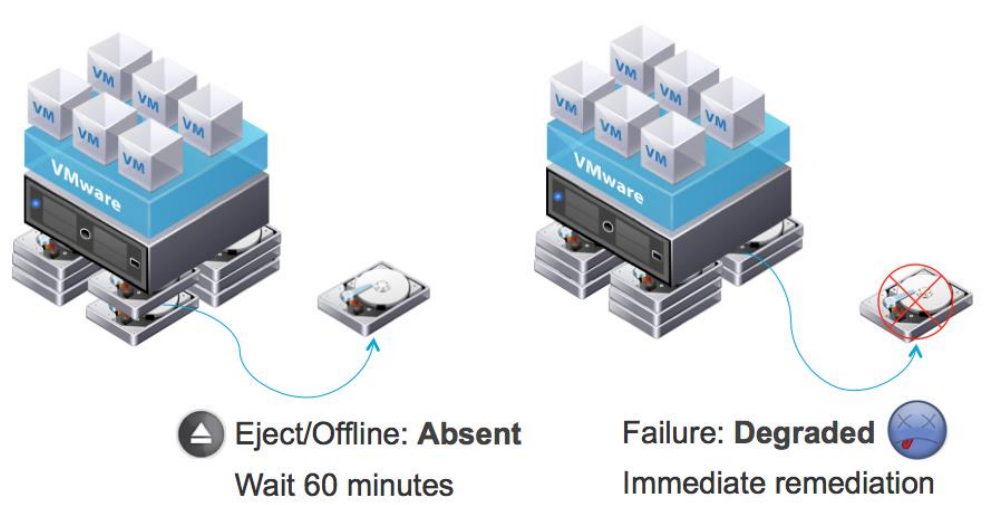
From the above image, left side a disk has been unplugged or offline may be reinserted or brought online, Virtual SAN treats the components residing on such a disk as ABSENT. If you look at the right side of the image, a disk has a permanent failure on an ESXi host participating in Virtual SAN cluster, the components that were residing in the disk will be marked as DEGRADED.
Virtual SAN starts rebuilding the DEGRADED components immediately it will wait for 60 minutes (by default) for the components that are marked as ABSENT to become available once again.If they do not, and the timer expires, Virtual SAN will begin rebuilding the components elsewhere in the cluster.
In order to rebuild the components, Virtual SAN will look for hosts that can satisfy placement rules like that 2 mirrors may not share hosts or fault domains and it also looks for disks with free disk space.
If such hosts/disk found, vSAN will create new components on them and start the recovery process if there are enough capacity and resources in the cluster. However, the exact timing of the behavior depends on the failure state( DEGRADED / ABSENT).
1) If the component is DEGRADED the data on that component is lost and won't return so Virtual SAN immediately takes the action and starts the rebuild.
2) If the component is ABSENT, Virtual SAN believes that the data may come back and the following optimization kicks in,
- Virtual SAN wants to minimize the time that virtual machines are exposed to risk due to reduced redundancy.
- A full rebuild of a component takes time and resources.
- If the disruption is short ( minutes), it is better for Virtual SAN to wait and allow the situation to rectify itself ( eg.reboot of host)
- If the disruption continues for long hours, Virtual SAN should restore full redundancy even if the component will eventually come back.
The Virtual SAN uses a configurable timer of 60minutes If a component has been ABSENT for 60 minutes, Virtual SAN will proceed to replace with a new component.
Use the vSphere Web Client to examine whether a component is in the DEGRADED or ABSENT failure state.
The pediatric dentist at Apollo Dental Sahakarnagar helps children overcome dental fear by creating a friendly and supportive environment for every visit. pediatric dentist
ReplyDelete